ChatGPT、Transformer 与注意力机制
by Teobler on 21 / 04 / 2024
views
上一篇文章我们大致了解了大模型的一些基本知识,这篇文章我们以 ChatGPT 为例稍微将目光聚焦到某一个模型的细节上来,聊聊这些模型背后的一些知识。这里我们就以 ChatGPT 为例,聊聊 GPT 是如何被训练出来的,以及 Transformer 大概是一个什么样的架构。
如果不加说明,本文的 ChatGPT 都指代的是 ChatGPT3
ChatGPT 是怎么被训练的
预训练
在使用 ChatGPT 的时候你会发现它对于人类世界非常了解,它不但能够理解你所说的,并且它的回答往往也条理清晰,这对于 2022 年的大家来说还是一件很震撼的事情,一改大家对原来人工智障的看法。
为了让 ChatGPT 能够拥有这样的能力,在预训练阶段需要收集整理大量(大约几千亿到两万亿token数量级)的训练预料,这些语料可以是来自互联网,也可以来自书籍。
预训练的初衷是为了让模型能够理解人类世界,并习得人类的语言和理解能力。但由于模型规模巨大且复杂,大模型展现出了“涌现”的能力,使大模型意外拥有了像人一样的推理能力,能够理解和解决复杂问题。在特定的条件下还能触发思维链。

Instruction fine-tuning
预训练完成后其实大模型已经拥有了认识人类世界的能力,也能在一定程度上处理一些复杂的任务。但是这个时候它依然是有缺陷的。比如理解简单的 zero-shot 的能力比较差,还有 few-shot 任务中去识别输入是否真实的能力也有所欠缺等等。
为了解决这些问题当然可以准备特定的语料和训练材料从头训练,但是从成本角度来考虑这是完全不可接受的,于是就有了另一条路 - fine-tuning。
fine-tuning 指的是在一个已经预训练完成的模型上,准备一些特定任务的数据进行额外的训练,这可以一定程度上更改模型的权重,使模型对某些想要的任务有更好的表现。通常为了不影响别的任务,在这个过程中可能会冻结一部分层。
而 Instruction fine-tuning 就是为了解决大模型更好地遵循人类给出的指令并生成更好的结果而进行的 fine-tuning。这整个过程本质上是有监督学习。在开始前会准备一系列训练数据,通常这些数据会被分类,比如是翻译类还是情感分析类,然后将这些数据转换为 prompt-response 对,一个 prompt 对应一个期望的 response。这些数据就将作为微调训练的数据喂给大模型。
从人类反馈中强化学习(RLHF)

经过前两步的训练,这个时候大模型已经有了比较准确的“回答问题”的能力了,但恰恰是由于前两步都是聚焦在让大模型回答问题更准确,而没有管大模型回答的问题是否“正确”。这就导致大模型的回答可能会违反人类世界的公序良俗,生成有害内容。于是又引入了 RLHF 作为一个额外的微调阶段。
这个阶段被分成两个关键步骤。
训练奖励模型
为了判断一个生成内容是否符合要求,为生成的内容打分,是一个比较直接的做法,比如如果将更符合人类价值观的生成内容打上高分否则打上低分。但是判断内容的好坏并没有一个绝对的标准,那么人工标注特定的分数也容易在不同的主观甚至客观上产生分歧。
所以一个改进的做法是将生成的一组回答按照质量从高到低排序,然后再将他们重新组合成元组对,一个元组对包含 prompt 和对应的两个回答,这两个回答会有特定的位置以代表质量的好坏,再用这些元组数据去训练一个奖励模型。让该模型明白什么是好的内容,什么是不好的内容。
尽管分辨两个内容哪个好哪个不好仍然可能产生分歧,但相对于一个特定的分数已经要好上不少。
强化学习微调
之后以这个训练出来的奖励模型为基础,让 gpt 使用某一些特定的 prompt 生成回答,用训练好的奖励模型对这些生成的回答打分,把这个分数作为强化学习算法的信号对模型进行微调优化。调整模型参数,以达到生成内容更加符合人类公序良俗的目的。
到这里 gpt 的训练过程就算是完成了,从整体来看。一开始的预训练阶段得到的是一个 base 模型,然后在 base 模型的基础上就特定的任务进行微调,这里的特定任务就是聊天,于是得到了最终的 chat 模型。如果在 base 模型的基础上使用特定的代码数据进行特定任务的微调,那么最终得到的就是 code 模型。
ChatGPT是怎么工作的
要聊 ChatGPT 的工作原理就一定绕不开 Transformer 架构,而要聊 Transformer 架构就又绕不开它的注意力机制,那么我们一层一层把它剥开来看这个让玩意儿是怎么工作的。
理解大模型的输入与输出是理解内部运算的关键之一,否则你会对里面的运算感觉摸不着头脑,所以我们会先从输入输出开始。
输入与输出

人类视角
假如我们将 ChatGPT 看作一个代码中的函数,给定一个输入,那么就会有一个输出。我们给定的输入当然就是 prompt,输出是一大堆相关联的文字。看上去它像是一个机器人在跟你对话,但其实这些对话只是一堆预测。
本质上来说 Transformer 的输出是给定 prompt 的下一个字的概率集合。举个 🌰:
给定一个 prompt - 今天早上,假设不同的语境下可能的句式有
- 今天早上我没吃早饭
- 今天早上下雨了
- 今天早上没有云
那么可能出现的下一个字的集合就可能是 (我, 下, 没),每个字可能有一个不同的概率,而这个概率是通过一系列计算得到的。于是最终这个输入输出就变成了:
- 输入 - 今天早上
- 输出 - (我 - 80%, 下 - 10%, 没 - 10%)
于是通过一些算法选中其中某一个字,然后将新的一句话(今天早上我)作为新的输入去预测下一个字,一直重复这个过程直到结束所有预测。
大模型视角
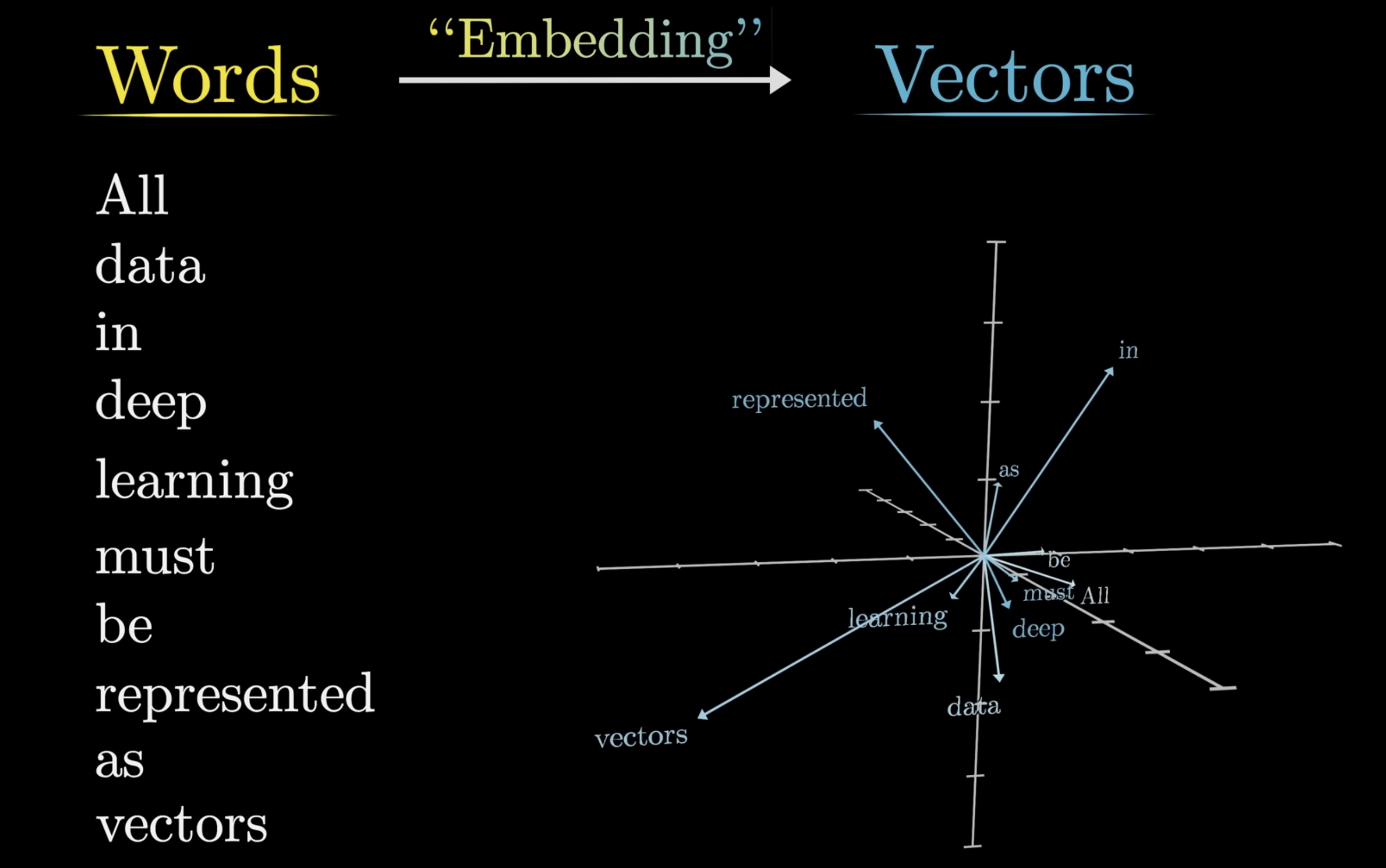
这当然只是人类能够理解的过程,比起人类拍拍脑袋就能理解一个词的意思,对于大模型来说是完全不一样的过程。为了预测下一个字是什么,实际上大模型靠的是理解各个字之间意思有多相近来完成的。于是聪明的研究员们想到了向量,如果两个字词所代表的向量距离越近,则表示这两个字词的联系越紧密,那么它们成为上下文的关系也会变大。
于是为了能够理解人类的语言,大模型需要先把 prompt 通过一个 tokenizer 变成一系列 token,然后将这些 token 通过嵌入(embedding)变成向量(vector),最终才会将这些向量作为 Transformer 的输入。
tokenize & embedding
这里的 token 可以理解成单词的一部分、单词或词组,甚至是标点符号,是大模型理解一个句子的最小组成单位,为了理解方便可以无脑将 token 理解成单词。而这些大模型已经认识的单词就是从预训练阶段学习得来的,大约有五万个,它们以矩阵的形式被储存。
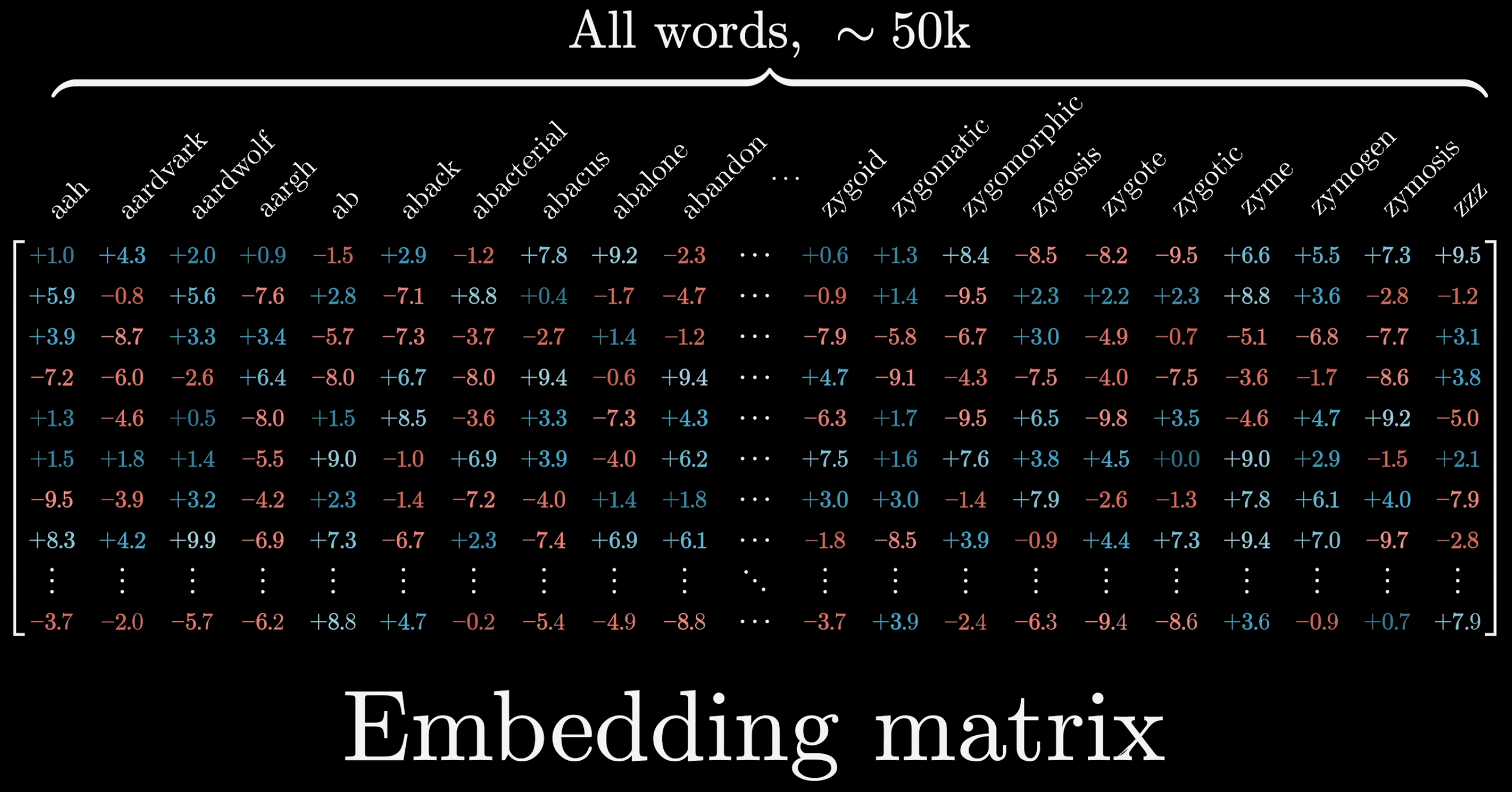
而向量的表现形式就是一个数组,每一项是一个数字,每一个数字代表了这个 token 在某一个维度上的一个数值,这可以被看作是一个在非常高维度的空间中的一个坐标,以 ChatGPT 为例的话,这个维度是 12288。
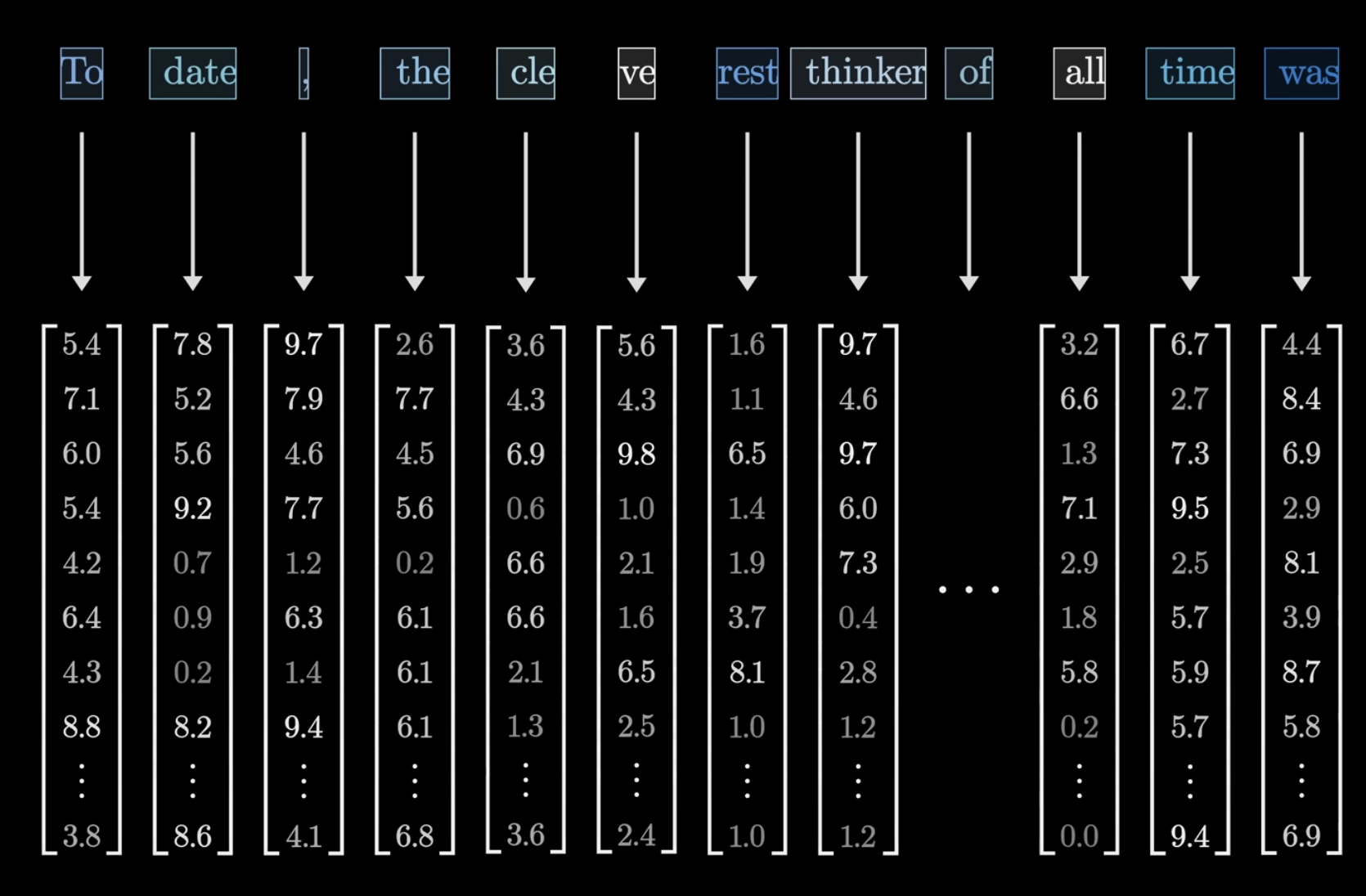
embedding 的过程其实就是使用一个矩阵来对每一个 token 做对照,这个矩阵的每一列都代表了一个 token,将 token 对应到自己的那一列也就变成了一个向量,这个过程就被称作 embedding。值得注意的是这些向量中还包含了这个 token 在整个上下文的位置信息。
又由于每一层能够处理的向量数量是有限的,以 ChatGPT 为例,每一层只能处理 2048 个 token,而每一个 token 有 12288 个维度,则每一层能处理的矩阵大小为 2048 * 12288。这也是 ChatGPT 上下文限制的由来,当超过这个长度,就势必会丢失信息,所以在人类看起来就像是 AI 得了健忘症,忘了之前说过的话。
输出
在经过 transformer 多层权重计算后,最后一层数据的最后一个向量汇聚了所有计算后的结果,包含所有的上下文信息,再经过 unembedding 等一系列处理后,就能得到一个待选 token 的列表,同时还能得到这些 token 出现在最后的概率是多少。
这里的最后一个向量的每个维度有个名字叫作 Logits,而它们计算过后得到的概率叫作 Probabilities。
但是由于 Logits 的取值都是正负不定的,所有 Logits 的求和并不是 1,于是就有一个重要的 softmax 归一化函数,该函数将每一个 Logit 代入以 e 为底的次方运算然后处以每一个维度该计算的求和以得到对应的 Probability:
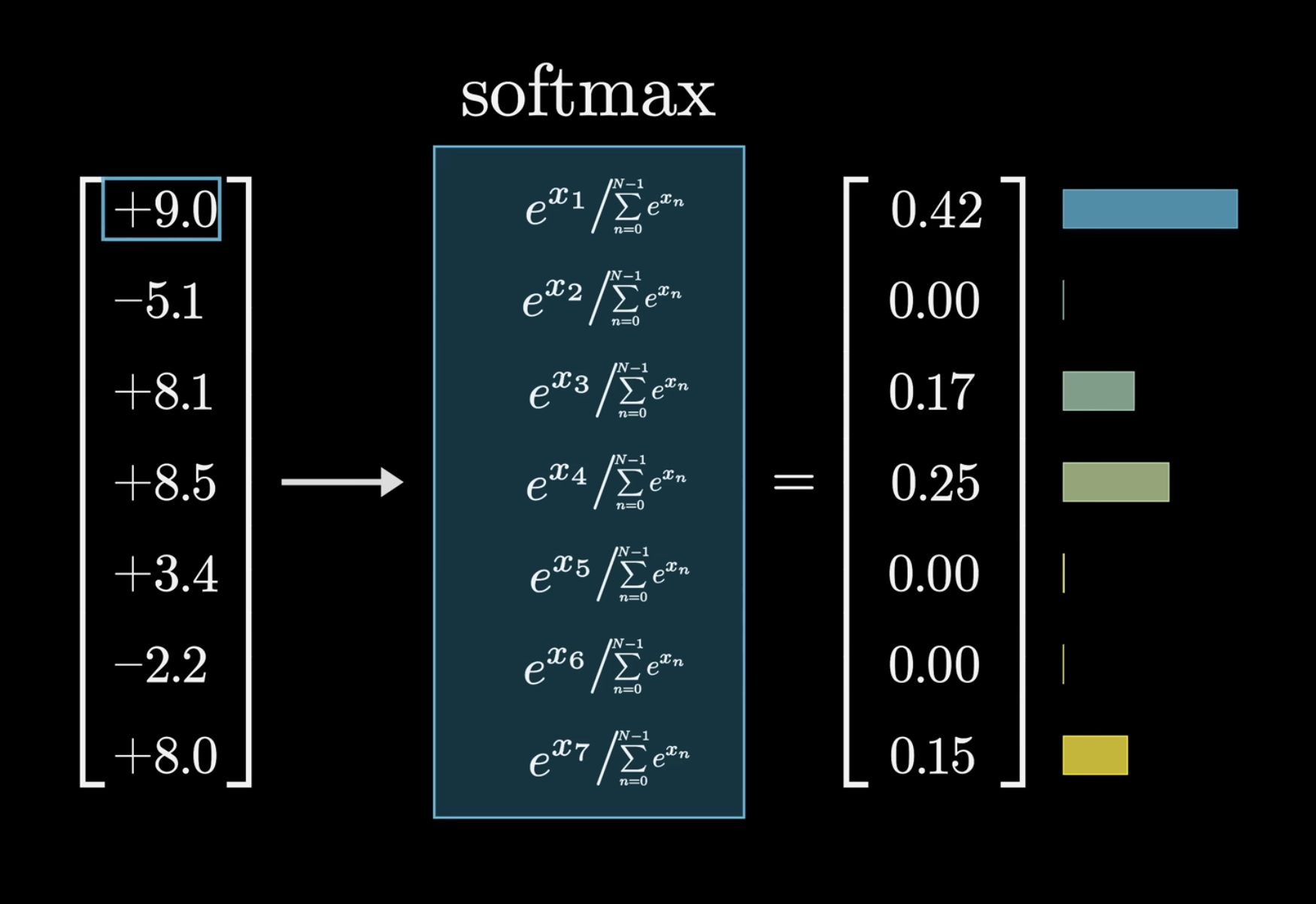
当某一个 Logit 的数值明显大于其他 Logit 时,它对应的 Probability 将会接近 1,其他 Logit 的 Probability 将会趋近 0,那么对于特定的 prompt 来说后面的 token 预测将几乎是同一句话。为了打破这种情况,可以在这个算式中加入一个常量 T:

常数 T 的作用是略微提升数值较小的 Logit 的权重,于是大数值的 Logit 权重就被降低,相对应的概率就将发生一些变化,T 值越大则这种变化越明显。这整个过程与热力学中的温度对分子的熵增影响很相似,于是这个常量 T 又被称作 Temperature。
在后面的文章中会讲到,这是大模型的一个重要参数, ChatGPT 的 API 将这个值的取值限定在了 0 到 2 之间,理论上来说这个参数没有限制,但是太大的 T 值会使得生成的内容毫无意义。
自注意力机制
理解了输入和输出,我们掐头去尾,进入到 transformer 最关键的步骤之一 - 自注意力机制。通常来说一个 transformer 由自注意力层和前馈神经网络层交替组成,有多少层这样的结构取决于这个模型有多少参数。
作用
用大白话来讲,自注意力层是为了让每个 token 之间产生联系,使得 token 能够在当前语境下能够表达当前语境的意思。比如 6,不结合语境你很难知道这是单纯代表数字6,还是在夸人。
自注意力层的目的是计算出一个原始向量应该加上一个什么样的增量,使得这个向量更贴近其在语境中的意思。例如星期六和你个老六两个词,自注意力层需要将六这个 token 的向量从单纯的六分别更新成为意思更贴近日期、星期、数字和形容、贬义、人物描述上来,两者虽然字面上相同,但实际含意完全不一样。
在真正的计算中,其需要关注的不仅仅是周围的几个 token,它需要关注整个上下文所描述的意思,所以自注意力层需要将整个上下文中的 token 相互联系起来,使得所有 token 的表达更为准确。这如同是一集柯南已经到指认凶手的阶段,最后一个 token 的预测是凶手的名字,那么为了准确预测,我们必须能够结合整一集的内容。
如何做到的
用拟人的方式来回答这个问题的话,每一个 token 会向所有其他 token 问 - 谁会影响我?,会对该 token 造成影响的 token 会回应这个喊话。
query key 向量
从计算层面来说,先需要将每一个 token 向量通过矩阵计算转换为另外的 query / key 向量,然后用 query 向量与 key 向量两两进行点积运算,得到的结果值越大,则两个向量重合度越高,则该 key 向量所属的 token 对 query 向量所属的 token 影响越大。
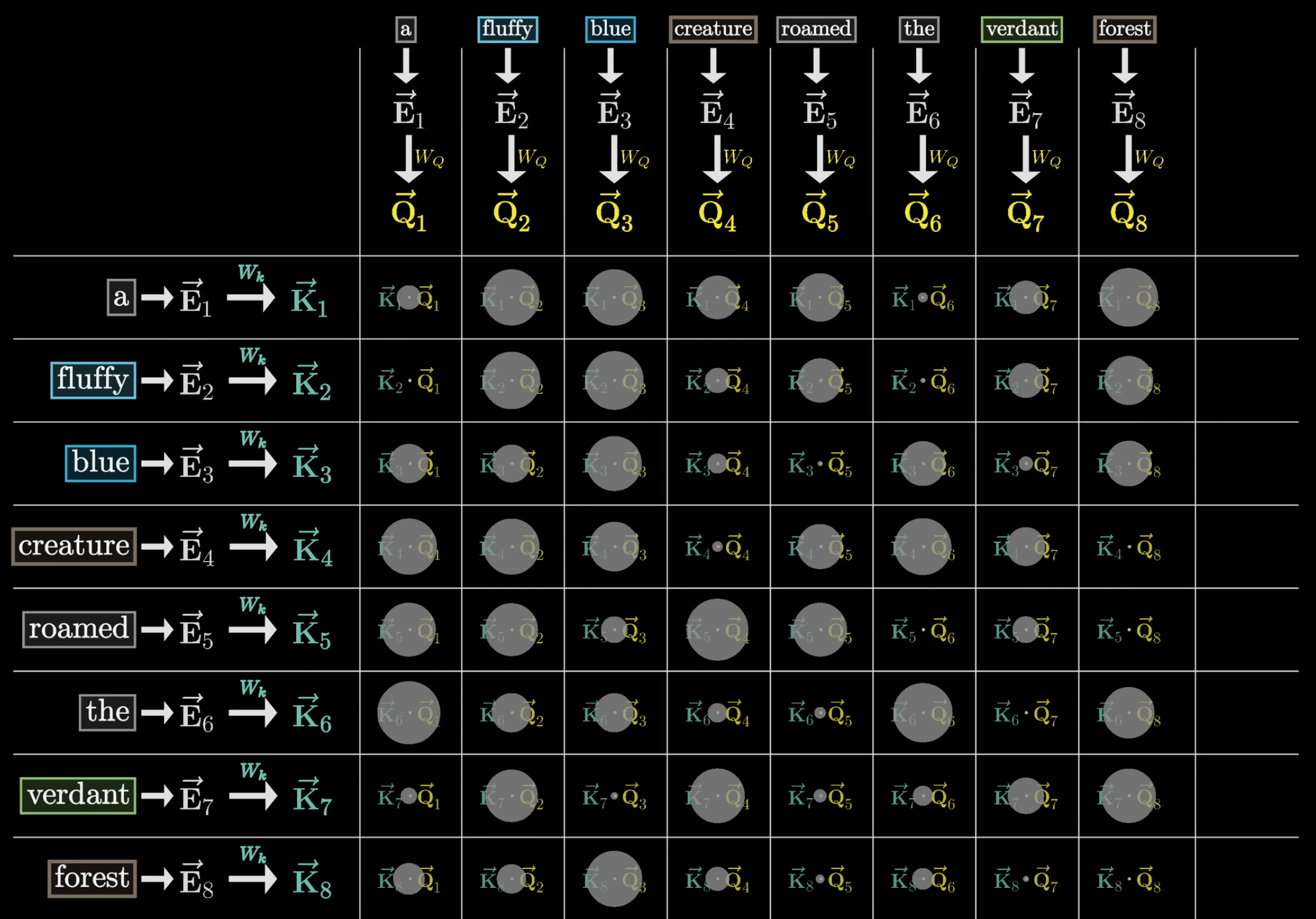
又一次因为我们需要一个权重来描述所有其它 token 对当前 token 的影响程度,用这个权重乘上另一个值进行加权求和得到一个偏移量,但是点积计算的结果是任意值,于是再次调用 softmax 归一化函数将这些任意值转换为概率分布。
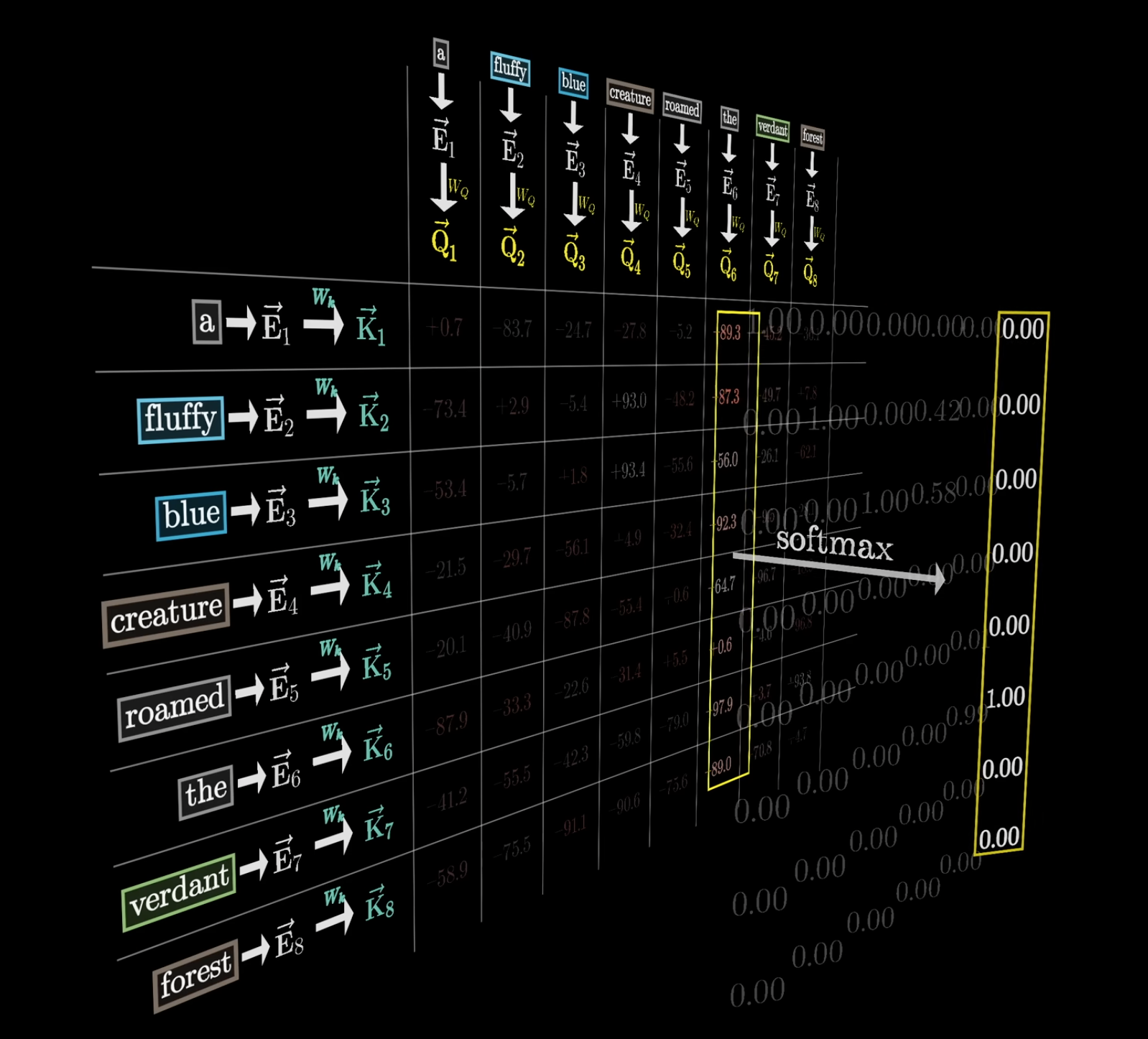
Masking
到这里我们需要引入另外一个新的概念。在训练时,为了提升训练效率,往往在预测一个长句的下个 token 时,不是单纯只做单词预测,会将这个长句进行每一个 token 的细粒度拆分。
例如一个 prompt - 今天的天气。训练时不仅仅会预测后面的 token 是什么,也会预测
- 今
- 今天
- 今天的
- 今天的天 的后一个字。由于这里已经知道答案,就可以建立一套奖励机制,用于修正接下来的预测,提升准确率。也正因如此,就需要屏蔽掉后面的 token 对前面的 token 产生的影响,否则在这个列表中只要我知道下一句话我很轻松就能预测上一句话的下一个 token 是什么。
这种屏蔽掉后面的 token 对前面的 token 产生影响的过程就被称作 Masking。
回到计算中,如果前面所讲到的,Masking 不能简单将所有数值换成 0,应该在 softmax 归一化之前将它们的值设置为负无穷,然后归一化之后这些值就会变为 0。
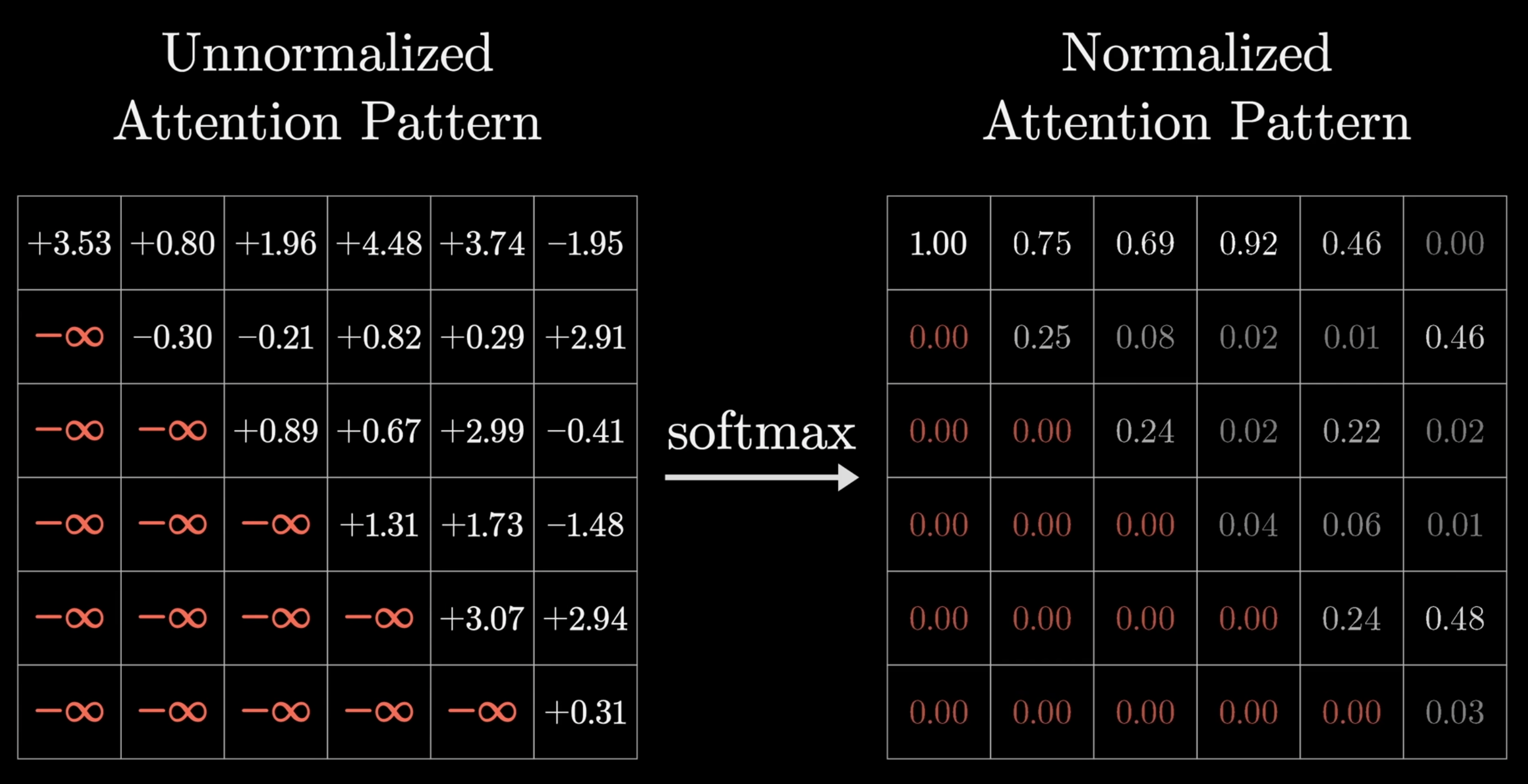
值向量
权重已经有了,现在我们需要更新向量的值了,这个过程相当于将 token 之间的影响力互相更新,使得 token 携带更多上下文信息,从而使表达更为准确。那么加权求和的的这个值哪里来呢?
在自注意力层中有另外一个值矩阵会将每一个 token 向量转化为一个值向量,这个值向量就是需要添加到被影响 token 向量之上的值。
最终计算
所以为了得到所有的上下文信息,被影响的 token 向量应该加上所有其他 token 的值向量和这些 token 的权重的加权求和:
更新后的向量 = 原始向量 + 权重1 * 值向量1 + 权重2 * 值向量2 + ... + 权重n * 值向量n
所以这里的加权求和就是我们想要得到的偏移量:
更新后的向量 = 原始向量 + 偏移量
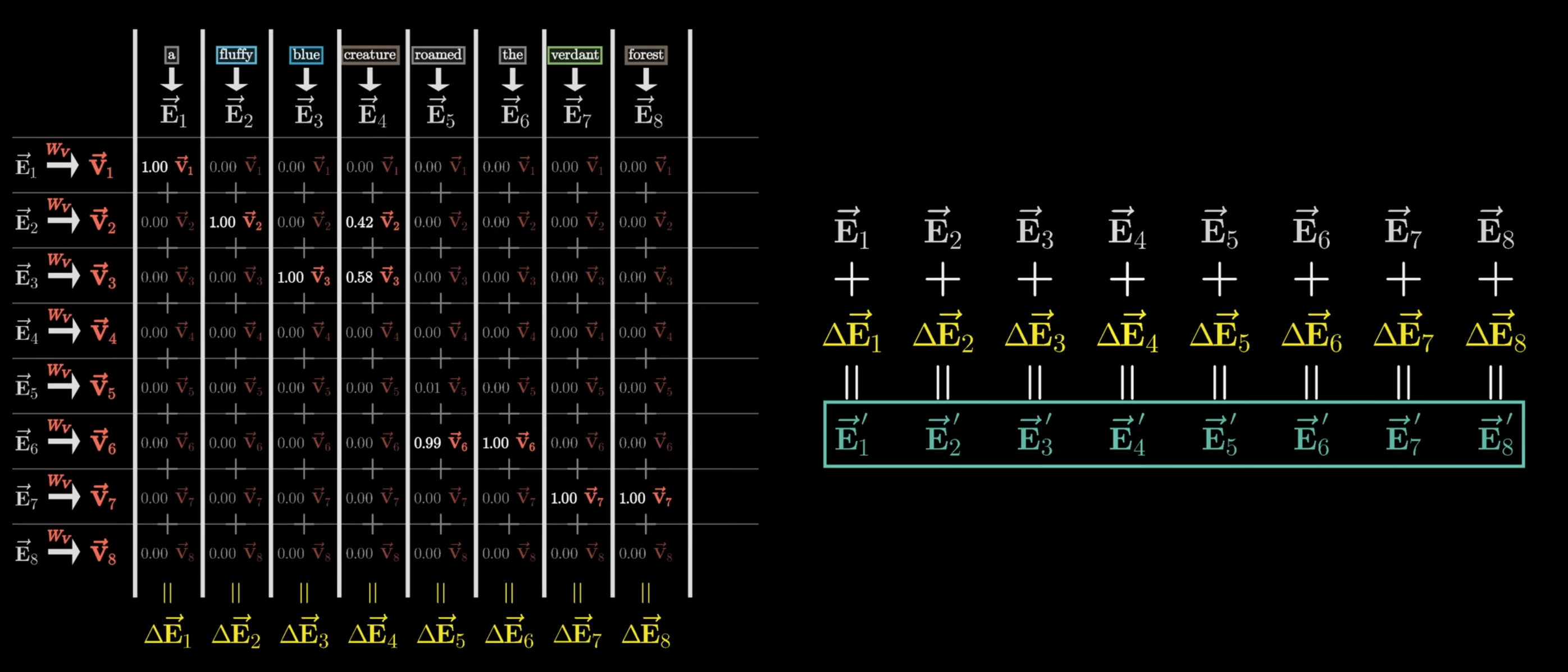
由于之前权重的存在,有的 token 对当前 token 的影响可能很大,那这个 token 的权重就是一个接近 1 的值,有的 token 可能对当前 token 几乎没有影响,那它的权重就会是一个接近 0 的值。
比如下面这句话:
李明,你个老六把我的键盘藏哪里去了。
老对六的影响就会很大,权重会很高,它将六这个字从数字定义成了完全不一样的意思;而个之类的字的权重就不是那么大;又由于 Masking 的存在,六后面的字的权重都将为 0。
总结

到这里自注意力层的工作就完成了,它依赖三个关键的矩阵(query / key / value)对 token 进行处理和计算,最终将上下文中所有 token 的信息进行互相传递,使 token 能够表达更为丰富的信息。如果你看过论文,就会发现论文中对这些计算的表示非常简洁:
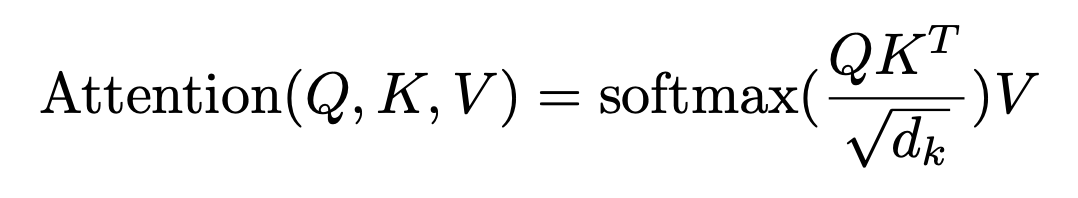
等式中的的 Q、K、V 分别表示了通过三个矩阵计算后得到的所有 query向量、key向量和value向量的数组。
而等式右边的分子乘积表示的就是query向量与key向量的点积运算求解相关度的过程。分母部分是我们略过的部分,为了使点积更加稳定,通常会将结果处以query矩阵和key矩阵维度(它们具有相同的维度)的平方根。
然后将点积的结果通过 softmax 函数运算求得归一化后的权重,再将这个权重乘以值向量就得到了注意力的结果。
多头注意力
需要注意的是上面的过程只是单个自注意力(self-attention)。往往单个自注意力关注的是某一类单独的影响。比如形容词会对名词产生影响,比如上下文之间可能互相影响(提到 Tom & Jerry 再出现猫和老鼠极大可能是动画形象)等等。
单个自注意力只能捕获到一类影响,因为它的三个矩阵是固定的,无法随时变更。为了捕获到更多不同类型的影响,在一个自注意力层中会并行运行多个不同的自注意力运算,这就是多头注意力(Multi-headed attention)。
以 ChatGPT 为例,它的单个自注意力层中有 96 个自注意力,意味着它有 96 组不同的矩阵去捕获 96 种不同的影响信息,以产生 96 个偏移量,这些偏移量最终都会被加到被影响的 token 向量上去。而这 96 组自注意力运算是并行发生的。
而整个 ChatGPT 架构中又有 96 个自注意力层,这意味着每一个 token 都将经过 96 * 96 * 96 次处理,这样大量的处理能够让大模型不仅仅能捕捉到语法和词法上的影响,甚至能够捕捉到语气、情感、行文风格等复杂的因素。
由于一些(我不明白的)原因,query / key 矩阵与 value 矩阵不具有相同的维度,而为了快速计算,矩阵和向量之间应该具有相同的维度,所以实际上为了使多头注意力计算效率更高,value 矩阵还需要经过一些特殊的矩阵拆分,将大的 value 矩阵拆分成两个以达到更快的并行计算速度。
而 Transformer 架构出色的点就在于它可以充分利用 GPU 比 CPU 多得多的核心进行大量并行计算(填了上一篇为啥不用 CPU 训练的🕳),于是它的参数规模相比起以前的模型就可能多很多。而在过去的深度学习领域被证实的一点就是规模越大往往最后的效果也会越好。这也是 Transformer 成就了 ChatGPT 的一个关键因素。
Reference
- https://www.youtube.com/@3blue1brown
- https://kimi.moonshot.cn/
- https://www.perplexity.ai/
- https://www.borealisai.com/research-blogs/a-high-level-overview-of-large-language-models/
- https://arxiv.org/abs/1706.03762